

Moderating Online Harms: The challenges of automation

ABSTRACT
This paper looks specifically at state-of-the-art (2020) technology for detecting, classifying, and moderating harmful visual content. It first provides a brief glossary for the vocabulary of the main methods and technologies used to discover harmful content.
It then goes on to describe the strengths, weaknesses, and limitations of the technologies and the factors that can be used to get the most out of them. The bulk of the paper covers 7 key considerations that a potential user in public or private sector groups should consider when starting, operating or regulating harmful content within an online platform. These considerations are supported by practical evidence and examples from Pimloc’s wide experience of developing and supplying specialist solutions for the classification, protection and moderation of visual content.
INTRODUCTION
There is widespread concern about access to harmful content in online imagery, audio, and text. This content may be deliberately sought but it can also be accidentally exposed. A noisy, headline policy debate about the responsibility for content continues between governments and tier one social media providers. These providers have complete control of their platforms and, in most cases, the technical capability to control content if they so choose. It has been well publicised that Facebook manages a team of 35k moderators along with a host of technical solutions for the automatic detection and moderation of their platform content. However most online platforms are created and their content controlled by much smaller players who have neither the technical ability nor, in many cases, the motivation to moderate their platforms’ content. Much of this content is benign but a great deal is intended to encourage or induce harm.
This paper is intended to provide strategic technical guidance to two target groups. The first is made up of commercial and non-governmental organisations which operate both online and internal platforms and wish to regulate their content to maintain internal ethical standards and remain within current laws and regulations. The second group comprises government agencies charged with policing online content for a wide range of purposes aimed at maintaining civil security.
The largest challenge facing both these groups is the massive volume of content to be moderated. Text and audio are essentially linear and more amenable to rapid, bulk review. But message-bearing content in imagery, and particularly in video, is deeply embedded and requires complex interpretation by the viewer or automated system. This combination of volume and complexity makes human discovery and moderation of harmful content in online still and video imagery wholly impractical. Human moderators need help.
TECHNOLOGY PRIMER
State-of-the-art systems for the automatic detection and classification of visual content make use of Deep Learning technologies. Deep Learning (DL) is a subset of Machine Learning (ML), which in turn is a subset of Artificial Intelligence (AI).
Artificial Intelligence, or AI, is the umbrella category that everyone recognises but an unhelpful description, packed with hyperbole. Literature and film have romanticised and warned of its capabilities since man started to write stories. It has spawned a sea of chatbots and recommendation engines with only a few specialist companies pursuing the meta-challenge of solving ‘General AI’.
Machine Learning, or ML, is a subset of AI that has grown in prominence, the ability of a machine to learn based on a specific range of inputs (sound, images, numbers). The concepts of regression analysis, where multiple observations of related variables to make predictions has been around and refined for over 200 years. Relatively simple, and therefore fast, ML tools, such as Support Vector Machines (SVMs), are commonly used to classify (recognise) objects in images from their characteristic features.
Deep Learning is a subset of Machine Learning in which a multi-layered network of simple nodes is trained to extract the key features of a set of observed data points, such as pixels in an image. The nodes perform convolutions (output dependency on multiple inputs) fairly similar to animal neurons, so such networks are commonly known as Convolutional Neural Nets, or CNNs. For some tasks, such as identifying the letters and numbers on a number plate, a relatively shallow network is generally sufficient. But for complex tasks, such as recognising a face among tens of thousands, a “deep” layered network is required.
LEARNING through TRAINING and TESTING
The importance of the second word in the title “Deep Learning” is often overlooked. Neural networks only work as well as the training data they are given. There are many different methods of training but the purpose of all of them is to define the optimal set of the multiple millions of interconnections and parameters used by the network to extract the key features of the dataset or image. Unsurprisingly, a network trained using millions of images of cattle is unlikely to be useful for distinguishing makes of car. (Incidentally, the simple set of lines between facial features so commonly used by media and in marketing material to illustrate facial recognition methods bears no relation whatsoever to the features used by a DL system to recognise a face.)
As will be shown later, the ability of the user to themselves provide and/or use large and relevant training datasets, or at least understand how the networks they will use were trained, is key to accurate detection of harmful online content.
MAKING DEEP LEARNING WORK
DL-providers should have a clear understanding of the domain in which they wish to operate. The most basic requirements are:
a) availability of representative datasets, essential for training and testing. This can be a particular challenge for the moderation of harmful content. Appropriate authorities need to hold and, where necessary, legally distribute datasets containing examples of the target material.
b) a DL-system which quantifies and indicates its performance with different test datasets.
Precision and Recall
These 2 terms have very specific meanings in Deep Learning. When searching a test dataset for items that match to a reference;
● Precision means the proportion of correct results, out of the total of items returned.
● Recall (also known as Sensitivity) means the proportion of correct results, out of the total of matching items in the test dataset.
A system tuned for minimal errors among the results (high Precision) will likely miss a relatively large number of true matches in a test dataset (low Recall). This is equivalent to testing a human operator by saying, “Make sure you don’t have any mistakes in your selection. If you’re not sure, leave it out.” The result is that some targets will be missed.
The converse is the instruction, “Be sure you don’t overlook any targets”, with the likely result that there will be mistakes in the selection. Between these two extreme instructions, there is a range of related values of Precisions and Recall which can be represented as a P-R graph.
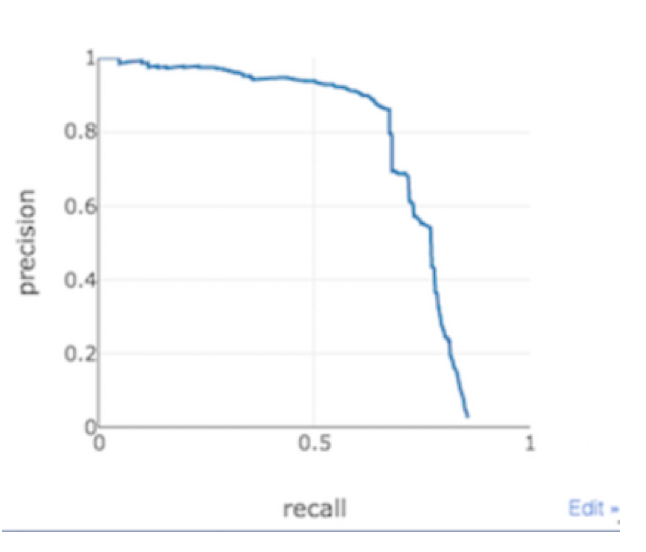
Perfect Precision and Perfect Recall are clearly both unattainable ideals that would be represented by a square-cornered graph with a “knee” at (1,1). When tested, the closer a system can perform to this shape, the better the match between its training and its task, and the more useful it will be.
Training is not necessarily a one-off event. The performance of a DL-system can be improved by the user correcting mistakes and adding examples of new content to the training dataset. The effect of these improvements can be tested by monitoring the Precision and Recall of the system as an on-going activity.
Ranking, Confidence Scores, Tagging
The default result of any DL search is the creation of a list of the entire searched dataset ranked in order of how closely each item matches the reference. The closest match heads the list, with matches becoming progressively weaker further down the list. With sufficient training data it is possible to give each match a “confidence score”, allowing a threshold to be set between matches and non-matches. Items with confidence scores above the threshold can be “tagged”, classifying them as matches to a particular reference.
Multi-Modal Searches
If items in an image have been tagged, it is possible to apply multiple filters, allowing multi-modal searches, for example, “find all images containing people holding a gun and wearing a helmet”. But relying on tags to make multi-modal searches completely ignores any relationship that may exist between the classifications being tested. There is an obvious relationship between wearing a helmet and carrying a gun. So, it may be more useful to create a classifier for “helmeted people carrying guns” rather than classifying and then tagging the two features separately.
Relationships and Intended Actions
The example above illustrates a basic relationship between two objects in an image. But more complex relationships exist and many of them indicate intent. An image of someone holding a knife in the presence of food suggests only benign intent and actions. An image of someone holding a knife in almost any other context is a potential threat. The classification of intended action can combine many other contextual clues such a location, pose, clothing, and the placement of objects. This is an area of active research but, as was made clear above, progress is highly dependent on the availability of training and test datasets.
PIMLOC’S INSIGHT INTO MODERATING ONLINE HARMS
Pimloc is a British tech company, which provides deep learning services for video security and data privacy applications. It has developed a world leading platform for the ingestion, detection, classification, and protection of visual content. Based on deep expertise in this area Pimloc believes that it is possible to develop and deploy systems which could automate and augment content moderation processes, to enable all companies, even those which are smaller and resource constrained, to comply with future regulation of online harms.
Pimloc has recently completed an exploratory project in this area to validate a system for the automatic classification of online propaganda images and video. This project provides practical comparison points for this paper and domain specific use cases.
AUTOMATION + AUGMENTATION
There are likely two ways in which automated online harm detection systems will be used:
a) ‘Automated monitoring and notifications’ which highlight known illegal/illicit or suspect content for review, and
b) Search and discovery tools that allow moderators to quickly search online platform content based on identified online harm content for specific people / objects / scenes.
Based on proprietary expertise and experience, Pimloc offers below some thoughts on the elements needed for an automated detection system to be effective.
(1) DOMAIN SPECIFIC DATA SETS
The more closely training data sets resemble the target domain, the better the detection results will be. Many providers have trained their systems on ‘general’ content and so perform badly when applied to more diverse and/or specialist data. However, generalist detection systems can be fine-tuned with specific domain data to improve their overall performance. Proxy data can also be used for tuning specific content classes where there are legal constraints on sensitive data ingestion.
(2) APPLES VS ORANGES
Detection and classification performance can vary greatly by content type – ie. detecting a gun is much simpler than classifying if someone is ‘posing with a gun’ for propaganda purposes, or determining the intent/meaning of an individual and/or wider scene context. For example, the following images from online news sites highlight some of the inherent challenges in the automatic detection of online harm content
The presence of a gun does not in its own right necessarily result in an image being classified as online harm. Automatic moderation of this image would need wider scene context to determine whether this is a friendly or online harm image.
This sort of challenge means that any automated system would also need the ability to trigger a manual review step and/or additional scene context could be added to the detection system to provide a more filtered set of results. Depending on the detail of any regulation, any system might need to include varying rules per object type – for example, automatically reject all imagery that includes logos of illegal organisations, but refer all content that contains weapons to a manual moderation work-flow.
It is also possible to train an automated system to consider additional scene context to provide a more reliable judgement on the harm of any image (for example, ‘gun’ + ‘pose/intent’ + ‘face coverings’ + ‘kneeling subjects’, etc).
(3) HARD VS SOFT RULES
As indicated above, some tasks can be fully automated, while other tasks will require some human moderation to make the final decision on whether they come under online harm or not.
Where the legal / regulatory requirement is clear, automation is likely to be simpler. Where wider context is needed to make a judgement, then deep learning systems can augment manual review steps and over time, these outputs can be used to further refine the system. An effective automated system must be able to accommodate both hard rules and a more judgement-based approach.

eg. Logo detection for known criminal organisations could be automated as a quick check to run on all image/video uploads.
(4) CONTINUAL LEARNING / IMPROVEMENT
Systems need to harness new data / learning on a continual basis to improve performance and to allow algorithms to evolve over time (in-line with changing trends/new interest groups/new illegal activities/new locations/new capture devices etc). These feedback loops can be partly automated as new ‘online harm’ images are detected and verified.
Online content platform providers with diverse customers would require a set of user profiles to manage the creation of new classifiers within the system. The dictionary of search terms created when a system is introduced would evolve over time.
(5) SHARING DATA ACROSS DOMAINS
In some business sectors the system learning described above is protected IP that is not shared across customers / platforms. However, for effective online harm detection aggregate pooling of data learning across domains is needed.
The ability to find ‘similar’ content across domains is essential to ensure automated detection across multiple platforms and to enhance system performance for each customer. However, it is possible to setup automatic system workflows that only allow the sharing of abstracted meta-data for ‘content of interest’ without needing to share the sensitive imagery itself. This would allow for wider data pooling from within specialist moderation teams to the benefit of all.
It is also possible to create a hierarchy of users with varying levels of system access; for example, super-users could create classifiers for new types of illegal content which could then be automatically deployed to the general online moderation platform (without end users needing any access to the sensitive data itself).
Integrated data privacy and security design will be critical to allowing the sharing and pooling of anonymised online harm data across providers.
(6) PRECISION VS RECALL TRADE-OFF
Automated system actions resulting from detections (ie. notifications, alerts, content take-down) can be tuned for varying accuracy vs precision thresholds on a task by task basis. For example, it may be better to have a smaller number of very accurate results (with some false negatives – ie. missed examples), rather than capture all the positive results and accept that they may also contain some false-positives. This trade off can be tuned, by task, to optimise any downstream work-flows. For example, if a platform has a very high volume of new content uploaded each hour and a very small content moderation team, then tuning the automated system for accuracy vs precision is likely to yield more productive processes.
Precision/recall (PR) curves vary by content type and data domain. These metrics need to be monitored as users annotate results. i.e. the system can output these numbers continually to identify how performance changes with new content.
N.B. Many AI providers quote precision/recall values for a given test set, under controlled conditions on a specific data domain. To be practical for comparison purposes these need to be validated against real-world data and across specific/relevant object/scene types.
For an automated online harm detection system, thresholds could be set by entity type to
trigger a different workflow step depending on the confidence level of detection required. Results over a higher threshold would trigger automatic actions, while results just under the threshold could trigger a manual review step. Over time, the outputs of the manual review step for the borderline thresholds would in-turn feed back into the system to improve overall results.
The PR curves for each online harm entity type would help determine the optimal thresholds for downstream workflow design. These curves could also be used to highlight content types that are generally harder to pick-up so more attention can be paid to improving them over time.
(7) AUTOMATING BIAS MONITORING
Specialist detection systems need to review algorithmic bias as an on-going activity (especially where algorithms learn/evolve over time); data sets for some online harm content may have inherent biases within them for ethnicities / gender/ age and locations. Systems need to run on-going tests to ensure that algorithms don’t learn these as determinant factors over time.
WHAT ARE THE IMPLICATIONS FOR PLATFORM DESIGN?
Drawing on these insights, Pimloc suggests that any effective, automated online harm detection approach would need to include the following:
- A central cloud-based system that can ingest, process, detect and classify all visual content from a range of online content providers. It would run detectors for online harm (objects, people, scenes etc), which would generate an abstract description for each entity which would be saved along with all verified examples of online harm content
- The system would need to keep a record of detected online harm content for future detection and system re-training
- Each customer / user would have a private account to review detections and to set automation rules for each online harm type (this could be set centrally by regulator, but it is likely each provider would want some customisable control over automation and workflow setup)
- Each platform’s detections would be viewable through a password protected browser; customers platform data would be private to each customer
- Each customer or user could have the ability to add new detectors / classifiers to run on their system data (these would not be added to the general system for all users be default – ie. if user_1 created a new classifier it would not automatically be usable by customer_2, also user_1 would not be able to change any of the global classifiers that have been set centrally)
- A process would be created for ‘super-users’ who can create new detectors / classifiers for the benefit of other approved providers; this allows for stringent quality checks to be put in place, monitored and reviewed
- Once ‘online harm’ images are detected in one platform they could be anonymously used to search for similar content in other platforms (for take down etc)
The initial setup of any system would involve on-going update cycles to pre-load detectors for all relevant online harm entity types and to tune results based on real domain data performance.
WHAT ARE THE IMPLICATIONS FOR REGULATION?
DATA ETHICS AND PRIVACY
Taking this approach could generate a central database of online harm content that could be continually added to from all providers. Pooling learning and capability in this way is important, but raises the question of who is accountable for the performance of specific algorithms for detecting online harm, how any detected data should be stored and who should have access). Should the regulator verify systems against legislation and then make those available to the private sector? Or should each platform provider interpret regulation and find their own solutions?
There are open questions around the right balance of central vs local provision and control, and the right level of data sharing for security and data privacy.
TECHNOLOGICAL MATURITY
The approach described in this paper, in which an automated system provides high precision/recall performance on the critical/general detectors across all providers, but also allows for tuning results for individual providers and their workflows, involves a series of technological stages of rising complexity and reliability. The main technical building blocks are detailed below individually with a viewpoint on their current maturity.
Detecting a distinct ‘object’ or ‘person’ within an image or video is a solved technical problem and can be built into an automated system
Detecting a range of ‘objects’ or ‘people’ in an image or video is a solved technical problem and can be built into an automated system
Classifying scene context in an image or video is an on-going academic research area, but results are already good enough for some content types for augmenting manual review processes.
Classifying activity from temporal data in video has already been the focus of lots of academic research (understanding the sequences of activities from multiple frames). This research work would need further development for specific online harm activities and domains.
Classifying intended action with an object in a single image is a difficult challenge and an open area of academic research; this needs other contextual cues from people / pose / clothing / location as proxies to inform judgement.
There are active research and development activities running across all these areas in academia and the private sector. Automation and augmentation solutions are already good enough to support wider content moderation, outside of the tier one social media platforms.
PIMLOC’S EXPERTISE IN THIS FIELD
Pimloc’s platform powers two products: 1) Pholio; A system for identifying specialist visual content and 2) Secure Redact; A system for anonymising sensitive content in video. Pimloc’s system for content detection also provides a host of search and discovery tools for locating entities within large image and video collections and streams.
Pimloc’s system for content detection / moderation could deliver the approach described in this paper and would also provide broader search and discovery capabilities as a direct by-product. Customers would get a system for moderating content, but they could also have a powerful visual search and anonymisation solution for wider content.
If you want to find out more please contact: simon@pimloc.com.