

Do you value your data privacy over child safety?
Wider reflections from Apple’s child safety updates.

Apple recently launched some new child safety features for users of their Messages smartphone application and iCloud photo storage, which were developed to help protect children online whilst still maintaining the usual data privacy and security controls for Apple users.
These updates attracted lots of backlash from privacy and security communities, resulting in Apple withdrawing their new solutions whilst they take onboard wider consultation and review. No one would argue with Apple’s root objective for proposing these updates - to help prevent the spread of Child Sexual Abuse Material (CSAM) online - but the direct and indirect implications of how the solutions are architected and governed encompass lots of trade-offs; all of which need to be considered from more diverse and informed perspectives than are usually required in deploying new software updates.
This case highlights how the latest technical developments in AI, encryption, image classification and data management are being live tested against the lenses of individual safety, data privacy, ethics, data sovereignty and national security. All in the wider public spotlight of ‘big-tech’ regulation, with associated sensitivities around content moderation and a general distrust of automated surveillance solutions.
The question of how to balance child safety alongside data privacy is not a simple one – not even for Apple who have principally put data privacy at the heart of their brand and products in recent times.
In this article, our aim is to cover:
Part 1: A review of the child safety technology proposed by Apple for its Messages application, with reflections that affect wider developments in the data privacy space.
Part 2: A deeper review of Apple’s proposed approach to detect CSAM content in their iCloud Photos solution, with the critical questions it raises for all of us dealing with the management of personal and sensitive data online.
If you are short on time you can skip ahead to the key takeaways that are listed at the end of the article; these apply to all businesses building products and services that use or process user data.
It’s not intended to provide a specific opinion on whether Apple’s moves are good or bad, but more to highlight the challenges that this case raises, and their implications for all of us in sectors dealing with a growing volume of personal and sensitive data.
These are areas we are exploring on a daily basis with Pimloc. We are focused on the crossover point between data privacy, security, analytics, and increasingly ethics - helping businesses and individuals manage personal data captured in CCTV and other video formats responsibly (and legally). Whilst we do not specifically build products to help with the management of CSAM directly, we are very familiar with the technologies involved and believe this case provides a nexus point for exploring the critical questions that are emerging for all who deal with personal and sensitive data - be that in retail, healthcare, insurance, physical security, smart cities, or for individuals themselves.
What are Apple's two proposed solutions?
Apple announced two new child safety features at the beginning of August 2021. These were both aimed at helping protect children online and curbing the spread of CSAM materials. The first focuses on changes made to the Messages application that aim to provide some protection for under 18’s from unintentionally accessing ‘sexually explicit’ content on their smartphones.
The second is a more constrained case that focuses on the detection of a specific set of individual CSAM images when they are uploaded to iCloud. This solution applies to all user accounts and has conditions embedded into it that allow Apple to automatically decrypt user data when they pass over a threshold for the volume of flagged ‘CSAM’ content.
Part 1: Apple Messages

The first update applies to all under 18’s who use the Apple Messages application on their smartphone.
If a sexually explicit image is detected by the user’s device, they get a warning message before they are able to access the image in question. The warning lets the user know that the content they are trying to open may be sensitive and asks them whether they still want to open it. It also provides prompts for the user to think through the implications of why these images may have been sent and provides some links for where to go for help if you need it.
For under 13’s, there is an additional step where if the child in question does open the image (and they are connected to a family account that has been setup for these notifications), then their parents or guardian will get a notification letting them know that they have opened a potentially explicit image. This is likely to help younger users become more aware of sensitive content and will allow them to make more informed decisions about what they open – it also brings parents into the loop to support discussions around responsible online behaviour, and to be able to help children make sense of the platforms they are using.

Apple is providing an algorithm that runs on each user's device that has been trained to detect sexually explicit images. Images received by individuals on their smartphones, through the Messages application, are processed locally and do not get seen by Apple employees or other parties. Apple also states that the system does not report anything to Apple moderators or other parties, they don’t track and report which users are opening images that have been flagged, or who sent them, and they also cannot see the images directly. Although the application does send notifications to parents, we assume these messages are fully protected through their usual data encryption solutions and are also not reported or tracked by Apple directly.
Reflections from Apple's updates to Messages
Data Privacy
Under 13’s have their privacy preserved – Apple are unable to see the flagged images and do not get to track when or if they open them – but in return, elements of their privacy are given up to parents.
Apple is pushing content moderation and governance responsibility out to users and their parents.
This relies on willing users and responsible parents or guardians who can use these notifications positively to support their children as they come to grips with the pitfalls of online systems. However, not all under 13s can rely on responsible parenting or guardians, and the downside of providing more parental surveillance may mean that more vulnerable children may end up actually being exposed to more abuse from their family. The notifications will force a ‘conversation’, and in many cases parental requests to see the specific images and who sent them, could be cause for more arguments and exposure.
Child Safety
Some critics have raised concerns about the notifications, saying they could end up outing children’s sexual preferences by encouraging their parents to snoop on them. Whilst this is possible, it still relies on the children in question allowing their parents or guardians to see the images on their devices and will likely lead to them switching to other platforms if that was an issue.
For over 13s, the emphasis is fully on self-regulation. For some older children and teens who want to receive and share this type of content, it’s probably likely to push them to other platforms which have less safeguards in place over the type of data that can be received. If you take Apple at its word, older children and teens can keep their privacy fully intact - albeit they are allowing their ‘device’ to look at and classify their images so it can provide warnings.
Technology weaknesses
There is a broader question on the quality of algorithms used to detect sexually explicit content.
Quality is usually measured as a combination of false positives (ie. how many images were wrongly classified as explicit) and false negatives (ie. how many sexually explicit images were missed).
Image classification solutions are mostly trained using deep learning techniques, where algorithms learn patterns in specific data - in this case images of explicit content - so they can recognise them in new data sets. Once trained, these systems usually output a prediction and a score which can then be used to decide whether an image ‘is’ or ‘is not’ a specific thing (ie. a piece of explicit content).
Thresholds are then applied to these scores to allow companies to make trade-offs on the accuracy of their systems depending on the use case; ie. a very high threshold would provide more confidence that all flagged images are explicit, but would accept that the system may miss some examples (ie. false negatives). Whereas a lower threshold would give a higher confidence that all images that contain explicit content are detected, but would accept that some images flagged as explicit are actually ok (ie. false positives).
Bias
As with all automated systems there is always the need to understand any algorithmic biases, which, in this case, would be any performance variance in a system's ability to detect different types of illicit images, across the full range of ethno-demographic groups. The challenge here will be how to build a diverse test data set to evaluate this on an on-going basis, and then, once picked up, how to remove any undue biases from the system (or how to mitigate around them).
Ethics
In this case, we understand Apple has set a high bar for their thresholds to limit any false detections, but as they cannot see their users data this is a tricky metric to manage on-going.
Many other systems of this nature rely on feedback from users around detection accuracy and/or proxy sets of test data for on-going testing. They need to have access to other sources of ‘explicit’ images to make sure they can maintain quality of detection over time. Given the scale of explicit images online, we assume this is a manageable case but does open up ethical questions for Apple (and others) directly on how to build these data sets; who has to look at them and how they manage them on-going.
Governance
This also opens up the question of what else Apple could use this solution for and how they make judgements of what is deemed explicit across cultures, geographies and age groups.
Is Apple responsible for determining what they judge as ‘explicit’ for all global users or would they give concessions to various countries, organisations and groups who may have vested or divisive views on these areas? Who gets to decide what our children should be looking at?
This is an area where company values, principles and brand become more critical – especially given the disparate, geographic nature of regulation in this area. How do companies operate in countries without strong legal frameworks for sensitive data management, how do they stay transparent in what they are doing and how do they hold themselves to account?
Part 2: Apple iCloud Photo storage
Whilst it was wrapped up in Apple’s wider child safety announcements, their planned updates to iCloud photos have some very unique characteristics that warrant deeper investigation. Aside from the specific technologies used, there are three distinct differences from the Messages updates:
Apple has created very specific conditions within which it WILL be able to access and review users iCloud images directly (after a user’s account tips over a specific volume of identified child sexual abuse material). All user uploaded images and associated metadata remain private and secure up to the point the threshold is crossed - Apple is unable to see or track any matched CSAM content until this point.
The system is not looking for ‘sexually explicit’ materials in general (ie. it’s not looking for exposed body parts and flesh), it’s actually trying to identify specific individual images that have been selected. In this case, it’s trying to find an exact or close to exact match against a known set of CSAM images that have previously been documented as part of criminal investigations.
Apple does not receive or have access to the CSAM images directly. They receive a file that includes a set of abstract numerical hashes for each image supplied by a 3rd party organization (in this case the NCMEC database (1), which is also used by Facebook and Microsoft for similar purposes). Each hash is a representation of each image held by the NCMEC database (not an image itself). Apple does not directly control the process that is used to generate the supplied watch-list of image hashes, and it cannot directly review or analyse the specific images that are being looked for from the hashes alone (2).
So how does the technology side of the solution actually work?
Apple separates the data pipeline into three areas; the CSAM hashes, the Client device and iCloud.

CSAM Hashes
The hashes that represent the CSAM images from NCMEC are loaded directly onto user devices. These are abstract (quantised) representations of images and not the images themselves (3).
Client Device
The CSAM hashes are then embedded onto each end user's device. Once loaded, the hashes can then be used to check for matching NCMEC images when users try to upload new photos to iCloud.
Before an image is uploaded to an iCloud account, it is first run through a hashing algorithm on the users device (using a similar approach to that used to generate the NCMEC hashes) to calculate a unique hash for the image being uploaded - which is then compared to the pre-loaded CSAM hashes from NCMEC.
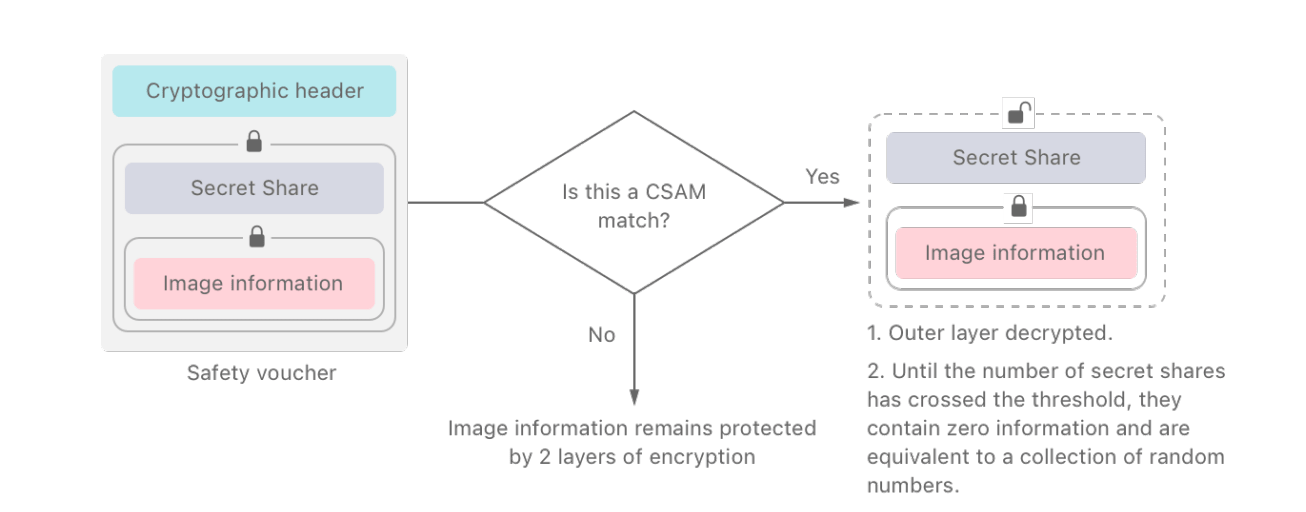
If an image match is found, this information is stored and encrypted into a safety voucher on the user's device - with the image and associated safety voucher both then being uploaded to the user’s iCloud account in encrypted form. At this point, the user, and Apple, have no direct awareness that their device has matched one of their images to the NCMEC’s CSAM hash list, nor that a safety voucher has been generated and passed into the user’s iCloud account along with the encrypted image.
iCloud
Once the user's device uploads the encrypted image and safety voucher to their iCloud account, they are then both stored in encrypted form. Assuming this match does not tip the users account over the allowable threshold of matched CSAM data, then Apple is still unable to view any user’s images stored in the user’s iCloud account, and cannot track or access any meta-data held in the safety voucher (ie. they cannot access user images or any data on how many images may have been matched against the watch-list of hashes).
How to decide when to decrypt an account?
To determine when a user’s account should be accessed, Apple is utilising a ‘threshold secret sharing’ (TSS) encryption algorithm that automatically generates a decryption key when a user’s iCloud account reaches a set threshold for CSAM content.
Once the threshold is reached, Apple is then able to use the automatically generated decryption key to access the flagged images in the users account - so they can manually review the matched images prior to passing their details to the authorities.
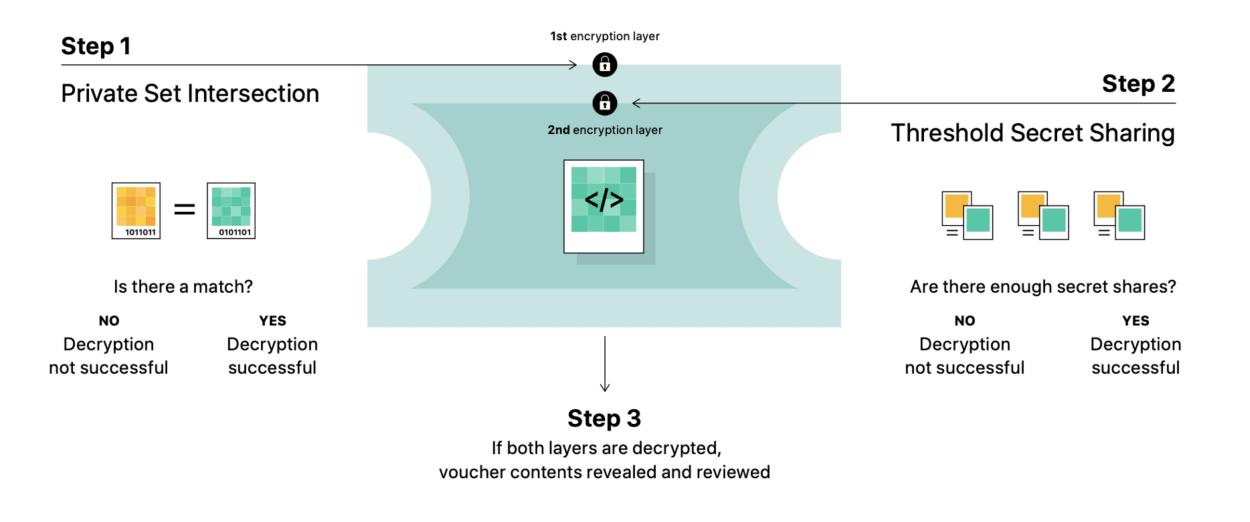
Apple’s breakdown of the decryption process
There are two levels of encryption that need to be decrypted to allow Apple to access a user’s images in their iCloud account.
1) A Private Set Intersection (PSI) algorithm runs on a user’s device to decide whether a specific image is a match. If a match is found, then the algorithm automatically generates a decryption key for the first layer of encryption for that image.
2) Once the encrypted image and safety voucher are uploaded to a user’s iCloud account, then the Threshold Secret Sharing (TSS) algorithm checks if there have been enough secret shares (ie. if the set threshold for matched content has been reached, ‘whether the user has uploaded enough flagged content’). When the threshold is reached, the TSS algorithm then automatically generates a decryption key for the second layer of encryption (4).
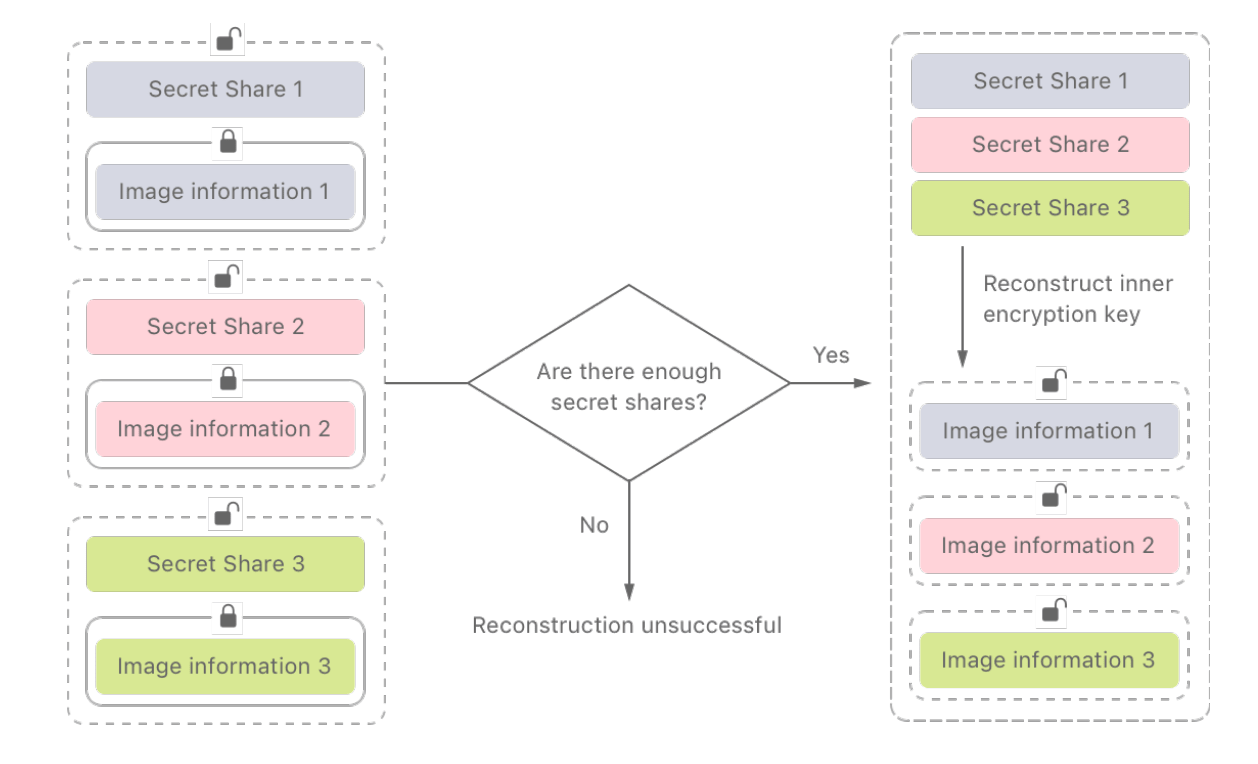
Once both these layers of encryption have been decrypted, Apple is then able to review the users safety voucher and images that were flagged.
The general view is that the encryption technologies selected are fit for purpose and provide strong protection and control for users' data - since their data is kept private and secure until a specific threshold for CSAM content is reached.
From a purely technical angle, this is an elegant technical solution to try and protect user data privacy alongside child safety for this specific NCMEC implementation.
Users' privacy is protected until an individual’s actions suggests that the value trade-off of their data privacy vs. child safety has been crossed, and their respective data can then be accessed by Apple. Until that point, users have full ‘practical’ privacy.
What’s missing from Apple’s announcement is details on the governance model, and values/principles that they will be using to regulate and manage the proposed system – ie. how they will stop this solution being misused, manipulated or subverted over time. It opens up a range of difficult technical, ethical, and national security questions with an associated set of complex data privacy vs. individual safety trade-offs.
This raises critical questions for the development of future data products and services

Apple’s proposed child safety updates raise a number of critical questions for all those providing online services that involve the processing or management of personal and sensitive data.
Q1: How to validate the trustworthiness of image watch lists?
What is the internal process (governance and sign-off steps) for adding a new set of image hashes to match against? What safeguards are in place to stop manipulation and to control how this system is used over time?
The ‘watch-list’ is the critical point of the data pipeline which could in theory be exploited to match users' content against other hash lists of images selected to depict political, religious, sexual, national or other preferences.
This could be done overtly where Apple has agreed to add a new class of watch-list data alongside CSAM content (eg. terrorist content), or it could be exploited covertly where specific watch-lists of image hashes are ‘poisoned’ with other image examples by external actors, with ulterior motives. There is potential to take advantage of the system for other purposes than just the NCMEC case that was proposed.
What process would Apple (and others) go through to decide whether to add a new class of image matching data to the system (ie. ethics framework, principles and governance structures)?
Companies need to be mindful of the different legal frameworks, cultural attitudes and levels of state control across territories; they need to be aware of who they are dealing with in each market. They need to have a clear set of values and principles that allow them to evaluate a wide variety of risks to be able to say no, even if some decisions inhibit their ability to do business in a specific jurisdiction. This is one area where a well-functioning, and empowered, ethics board can earn its money.
Once it has been decided to add a new class of image matching data, how can Apple (and others) audit the quality and representativeness of the images being matched?
It may not be appropriate (and in some cases, like CSAM, it may not be legal) for Apple to manually review the source images themselves, but there needs to be assurance that watch-lists could and would be deeply vetted before deciding whether they were appropriate image sets to warrant breaking individuals data privacy for.
Ultimately, it all boils down to whether users trust Apple to act responsibly in an unknown future, how they will behave and manage their service on-going - and how they will maintain the right balance of privacy and safety as online threats continue to grow and world politics further polarises.
Building trust in this area requires engagement with a wider set of external groups than usual, and more of a focus on transparency and governance than secretive tech companies are used to. Apple has ignited the debate with an ingenious technical approach (which is what they are famous for), but that needs to be supported with wider considerations on how they will behave and regulate themselves into the future (8).
Q2: Hot to set thresholds for breaking user privacy?
A trade-off between zero tolerance for CSAM data and certainty of accuracy of matched results needs to be properly established.
Apple made the decision to set the threshold bar very high for this implementation to ensure there is a significant level of certainty, based on multiple image matches, before they would be able to break individuals' data privacy.
This decision shows a very conservative approach from Apple, since they place more value on accurately identifying that an individual has been uploading CSAM content vs. the risk of incorrectly flagging an image in someone’s account.
The image hashing algorithms are more accurate than many deep learning based models, as they are matching individual images specifically, but they are still not 100% fallible. A high bar means that they may miss some individuals who fall just below the threshold (or take longer to pick them up), but they can be more certain that they are removing (or greatly reducing) any chance of false-positives (ie. breaking user’s privacy for the wrong reasons).
This is an area where different stakeholders and interested parties may want a differing threshold approach to allow more or less surveillance of ‘suspect’ accounts.
The sliding scale of data privacy vs. child safety provides a practical framework for exploring the options – 100% child safety would require all data in all accounts to be reviewed (at the expense of everyone’s privacy - 0% data privacy), 100% data privacy would protect ALL user data (at the expense of child safety - 0% child safety).
The decision for all companies is where to position yourself on the axis; Apple’s solutions usually sit at the extreme end of the data privacy axis, which has brought them lots of criticism from law enforcement and national security agencies who are unable to directly gain access to user data with warrants (even in times of national emergencies).
These new child safety solutions move Apple off the extreme of the axis, which is a much harder position to regulate, monitor and communicate because it requires complex trade-off decisions to be explained, and places direct value judgements on individuals' data privacy vs. in this case, the risks they may pose to children.
It also raises the question of what process would be required to change thresholds over time – either as threat levels increase or the accuracy of technical solutions improve. This is an area where a business’s ethics, values and principles are critical to allow them to communicate intentions, and to help steer all the micro decisions that are made in product and service development every day.
Q3: How to review the accuracy of a fully encrypted and private detection system?
Hash matching algorithms can provide accurate results, but some use cases may require other image classification methods to be deployed in order to be effective. Apple's NCMEC case is tightly constrained around the specific data set of CSAM image hashes they provide.
This allows for rigorous testing of the selected algorithm by NCMEC; they have access to the source imagery and algorithms. NCMEC could also be set up as covert users (with appropriate legal exemptions) to upload sample images directly to their iCloud accounts from the source CSAM images, to check they are picked-up by Apple’s system. This would provide a route to continually evaluate false-positive and negative rates – assuming there was deep partnership and cooperation between the two parties. This would place quality control partly on the supplier, and again would open up questions of trust and audit-ability between Apple and supplier.
Apple only get to check matched data once a user crosses the threshold; over time, this would give a measure for any false-positive rates, but there would be no way of calculating a false negative rate (ie. how many CSAM images were missed). Given Apple has placed more value on being certain (vs. picking up all examples), this would support their position.
The combination of the algorithm approach used, the constrained data set, and high threshold provides a balanced level of risk for the proposed CSAM detection solution.
If; however, the scope of detection was broadened to any sexually explicit images containing children, then other algorithm methods would be needed (likely deep learning based) to detect unseen images that contain these types of content. This would be an area that would have less certainty on matching vs. individual hashes; it would pick-up more examples of target content, but would also generate many more false detections. This would be a much more difficult scenario to monitor system accuracy, and would provide less certainty on outcome. There is no fixed test data set; Apple (and/or suppliers) would need to run their own data collection and testing in parallel using non user data. This introduces challenges of domain shift, and a reliance on accuracy measures from test or proxy data only.
In this case, the level of false positives may be too high to allow for automated decryption solutions, as it would result in many user accounts being incorrectly flagged and accessed. A company could measure false-positive rates when they access decrypted accounts, but that means they are breaking user privacy in order to test and improve their product.
In other domains, that may be something certain users would be happy to opt-into as a way to help improve the solution, but that’s not something that works for explicit content, as user’s should not be uploading it in the first place (and in many cases, it’s illegal to do so).
Deploying responsible solutions in this space requires a deep understanding of the weaknesses of the technology involved, so that they can be deployed responsibly with the right safeguards in place for their appropriate usage. This applies broadly across diverse areas of automation and AI systems, and unfortunately is still a complex area for many to fully comprehend. It’s also why many aspects of AI have become untrusted; as algorithms designed for one purpose are deployed or evaluated against others.
Q4: What actually happens when a threshold has been reached?
Who has access, what do they have access to, how do they validate the detections, do they need to make any value judgements, who do they need to report the incidents to?
In this case, Apple moderators may be able to review the matched images to see whether they depict CSAM data, but they will not be able to confirm if they match specific images. There is also the question as to whether Apple employees should look at those images themselves.
This is another area where trust is paramount; without full trust in the image hash matching solution (and the supplied image hashes), Apple would need to check the detected images themselves before reporting onto 3rd parties. In the proposed case for CSAM content from NCMEC, it may be that Apple is happy to just pass the user details and images directly to NCMEC for review, rather than needing to have internal employees carry out an interim QA step.
Once the user data is decrypted, Apple does then have the power to access those images. How they design their internal processes, and apply the right technical controls to them, so that only a specific set of trained and approved individuals can access them, will be another important area for careful consideration and transparency. This also opens up wider data security challenges, as once user images and accounts are decrypted, they become more accessible to malicious attack (from insiders or 3rd party actors).
Q5: How do we hold a business accountable to global standards when laws and regulations are all local?
This is one area where big-tech has an important role to play in the spread of responsible standards for data management, especially in regions with limited legal frameworks in place for the management of personal data.
Outside of humanitarian areas, there’s no precedent for global law or regulation setting; businesses are bound to the varying legal frameworks and practices of each country they operate in.
Global firms who operate responsibly have to measure themselves against the same set of values, principles, and standards everywhere. They need to abide by local laws in the jurisdictions they operate, but need to be resilient to varying state motives and levels of regulation – they need to be clear on how they will operate and manage data.
Global businesses need to balance the different data privacy risks of customers in each country against the individual risks and safety of specific groups. Where they operate in countries with low data regulation and legal frameworks, the onus is on the tech company to do what’s right for their individual customers.
This is a really big challenge and one that is again suited to be picked up by an empowered board with diverse representation; requiring big-tech to work closely with the public sector, the markets they operate in, and to design ways of working and collaboration that bring in a broader understanding around the insights and national security risks from data vs. just the usual product/market considerations.
This is an area where private businesses can learn from the UK public sector, who are used to regularly going through public consultations on major projects to get input from a wider section of society and special interest groups. Public consultations can be lengthy, and sometimes stifle innovation - but the private sector is free to design review processes that could be more productive and allow them to build real communities and collaboration with outside groups. Over time, these relationships could become real assets; fostering greater trust with users and regulators alike.
Q6: How can we help educate consumers on the implications of these types of solutions?
It’s highly unreasonable to expect that all users of online platforms across the globe need to become informed on all these areas, but the companies running them do need to be. Companies also need to think about how to communicate their position on the ‘data privacy vs. safety axis’, along with the values and principles that will govern how they operate in the future.
Privacy has become a marketing battle-ground for big-tech in the last couple of years, and is spreading to other sectors; especially those who are responsible for the management of large-scale personal, health and other sensitive data. Businesses need to go deeper on how they manage data and the associated governance models, and critically, how they can communicate this in an easy to understand way.
The critical issues are now smashing into each other, and will need a new type of narrative and ways of working that are baked in ethics, privacy and trust. The people around the decision-making table will need to be from more diverse backgrounds and represent more diverse fields; they will need to be able to make responsible decisions and be accountable for them, and they will need to open themselves to wider review and critique. These are not simple tasks, but a way through has to be forged.

Key takeaways for all data businesses
It's critical for businesses who deal with personal data to have very clearly stated values and principles that they can be judged against; the technology landscape is too complex for everyone to understand in detail, people need other heuristics and simple validation points to decide who to trust with their data.
Transparency and accountability of data practices and governance models will become critical pillars to build trust with customers and partners. If companies are very clear on how their systems work, then users can decide if they agree with the platform's position on data privacy and whether they are happy to share their data.
Ethics is not just a job for an ‘ethics board’, but should also sit within a range of departments. Companies need to bring people into the product, tech, commercial and advisory teams who understand ethical frameworks and can apply them to real business problems.
Companies need to take responsibility for who they sell to, partner with, rely on, and their processes around transferring data. Companies need to acknowledge that they need high global standards that cut across geographies and political boundaries.
There needs to be more collaboration between public and private sector companies to allow for responsible product development, alongside effective regulation and sharing insights around the ever changing risk landscape.
Companies need to spend more time thinking about how their technical data solutions could be subverted or compromised over time. They need to draw on wider capabilities to review the indirect risks of new automated solutions.
Companies need to open themselves up to wider review and collaboration in their development processes. There are more things to consider than product / market benefits alone.
Final thoughts
In isolation, you could argue that the announced Apple solution would just result in bad actors moving onto other fully secure and encrypted platforms (ie. those with 100% privacy), and that the net result is no change for child safety. But, if more and more platforms follow suit then the choices for sharing illegal and illicit content will shrink.
Some of the current push in this direction is being driven by the emergence of new legislation and regulatory powers to improve child safety online, as per the recent UK ICO Child Safety Code - but whatever the reason, it’s another small step forward in working out the best way to protect our young ones from undue harm online.
Thanks Apple for bringing all this to a head, and for pushing more of us to think through the deeper implications of managing data privacy alongside individual safety.
References
N.B. There are some theoretical approaches that could potentially be used to generate noisy ‘synthetic’ versions of similar images from the hashes but nothing that is currently usable and proven at scale.
There is a significant amount of research and academic publishing on image quantization and hashing approaches with known good levels of accuracy and active deployments. There is well documented academic research and associated open source code that allows transferability in approach and standards across businesses and their services.
The TSS algorithm is based on well renowned and peer reviewed academic research. Apple included further academic appraisal of their selected encryption solutions as part of the public information they released with the planned updates.
N.B. Apple’s heavily engineered approach is required because by default, Apple encrypts and protects data for all their users. They are adding in some additional conditions where they will break their privacy contract with individuals who pose significant risks to others. This is not the case with many other platforms who run more open systems where internal moderators and developers can readily access user data for review and new algorithm training.