

Democratising art history with AI

Opening the world's art collections for new discovery
Through the application of the latest AI developments in image classification we have developed a pioneering solution that allows the immediate opening of large digitised image collections without the need for tagging. Rather than focus on creating a set taxonomy of terms we have developed a platform that instantly removes all barriers to search; allowing for free navigation and discovery of large art collections by art historian and children alike.
“A whole new paradigm in art search”
The accepted approach to cataloguing within the Art and Heritage sector has been built around creating a fixed taxonomy of terms where experts manually annotate digitised works (adding meta-data) so they can later be searched.
This approach has a range of inherent challenges that have been holding back the majority of the Worlds Art Collections from being made accessible online:
Time and cost involved in manual annotation; in some cases estimated at 10+ years for larger collections
The accuracy and consistency of tags across experts due to distortions from human error, bias and subjectivity
The descriptive limitation of tags, you can only search for the tags that have been created
It’s impossible for a tagger to know all the things that people will want to search for in a particular image; and even trickier to take into account future evolution of tastes, trends and language that all have a bearing on what people will be searching art collections for in the future
Many collections have no meta data at all or base their search purely around Artist / Subject and maybe Date which renders them in-accessible for all bar a few expert users
The net effect of these barriers is that most digital art collections remain inaccessible for most people (even with the growth in art digitisation efforts we are seeing across the sector). Many of the institutions we have engaged with have only been able to annotate 5% of their digital works so far and of these only a small proportion of artworks ever surface within search results. The vast majority are just sat on servers gathering digital dust.
Searching based on static tags can be very frustrating…

There are now some online services that can auto-tag image collection (leading services from Amazon, Google, McSoft and Clarifai), you upload your images and get back a list of static tags for each of them, but they still fall foul of the issues listed above, they are still very costly for large collections (you pay per image) and you have even less control over the taxonomy of tags created or how they are applied – once applied they are fixed; they don’t evolve or learn as people navigate your collections.
TAKING A DIFFERENT APPROACH TO SEARCHING ART HISTORY
Pimloc has developed an AI driven solution that allows immediate searching of large collections without any need for tagging.
“It allows us to ask new questions of art history”
The system first indexes your collection (either in the cloud or locally) to extract all the abstract features in each image, starting with a few pixels up to the whole work. The system can instantly recognise 20k objects, styles and scenes and learns new language and meaning through its usage. Rather than compute and apply fixed tags the system just stores these abstract representations of visual elements across the collection ready to utilise based on what real users want to look for; at this point the system then optimises its results based on its latest understanding of the search query and corresponding image features – not a search against a database of tags.
Rather than just tag a collection Pimloc allows users to freely navigate large collections geared around how they want to search, putting discovery at the heart of the user experience. For every search the Pimloc system returns a ranked list of the whole collection with those most similar to the query at the top ie. the top few pages of image results are the ones that are most similar.
Rather than apply thresholds to only show results that are deemed ‘accurate’ the Pimloc system allows users to navigate through all results that are ‘similar’ to allow for wider discovery and exploration. The process of research and discovery within art collections benefits from fuzzy edges and overlap rather than binary separation.
If the user searches for something the system does not understand it instantly goes online to build an understanding of the term (by gathering a selection of sample images from the web which it then indexes to create a classifier) so it can return all images from within the art collection that are similar. Every search gets a response which the user can then browse, navigate from or even improve (users can quickly improve results for more specialist or long-tail terms which are the stored within the system).
To illustrate this new approach, I’ve included a few examples searches from the digitised Witt Library from The Courtauld Institute of Art. As part of the digitisation project, led by Tom Bilson; The Courtauld’s Head of Digital, Pimloc have indexed all the British artworks that have so far been digitised, which span from 1200 – 1799 (with a few modern works mixed in) in order to make them available for discovery.
A simple search of this collection for ‘skeleton’ returns a selection of works depicting a range of skeletal forms alongside images with similar content and/or styling (eg. armour / exoskeletons).
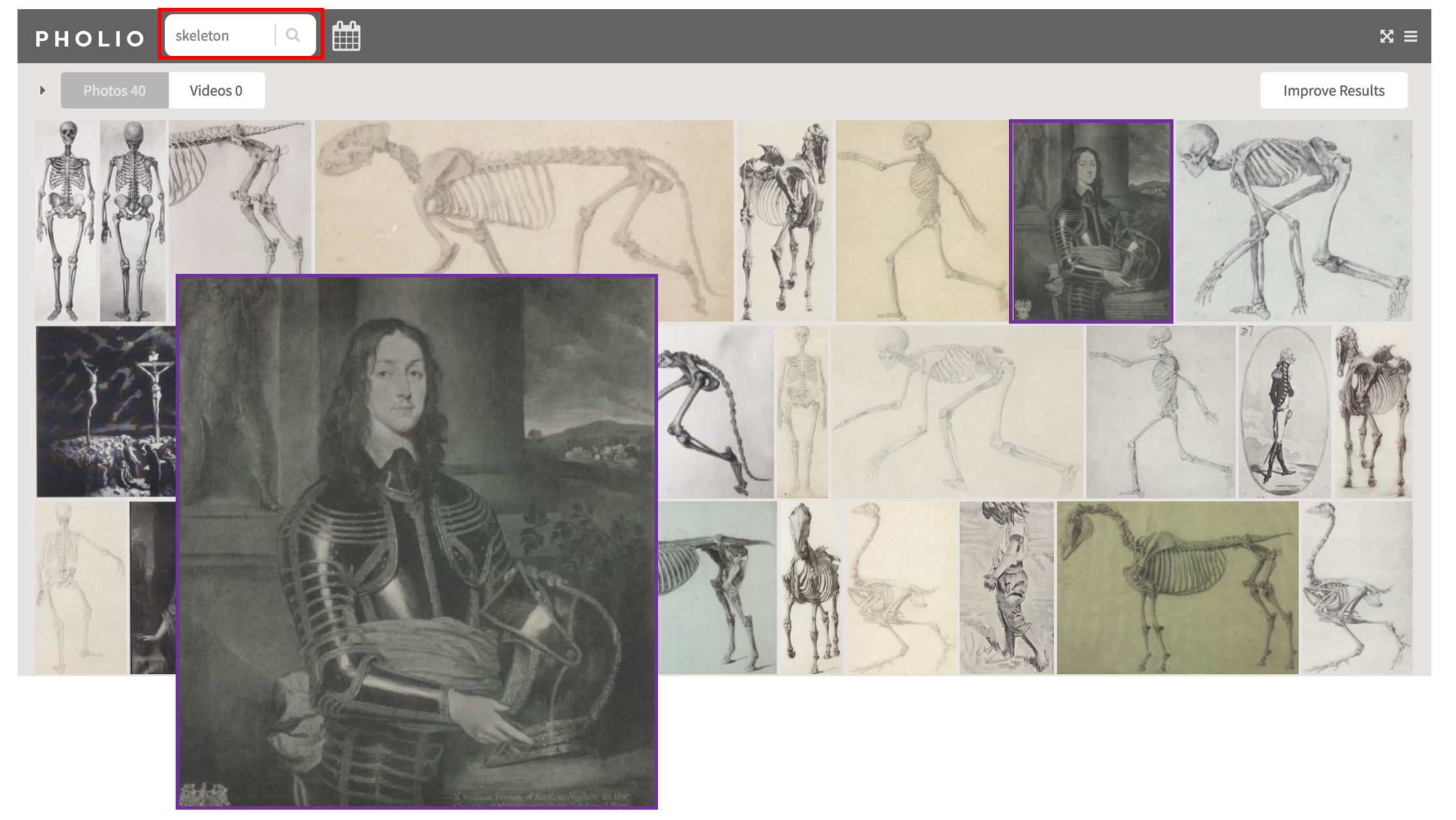
This allows the researcher or interested browser to make unseen connections and discoveries across very diverse subjects and styles of art. Freely reviewing the whole collection of art through a specific thematic lens rather than having to search within sections of collections based on their previously assigned taxonomy.
It’s very unlikely that the below painting of an Owl would have ever been manually tagged as an Angel, or that anyone would have searched for ‘Owls’ in order to find ‘Owls with angel’s wings’. In a more traditional taxonomic system this result would be viewed as an error, Owls are not Angels, but that misses the wider representation and symbolic nature of art and its interpretation.

Collections can be searched based on their geometric patterns, styles and colours providing un-constrained access to navigate, filter and explore a specific content area.

A search for <circles>
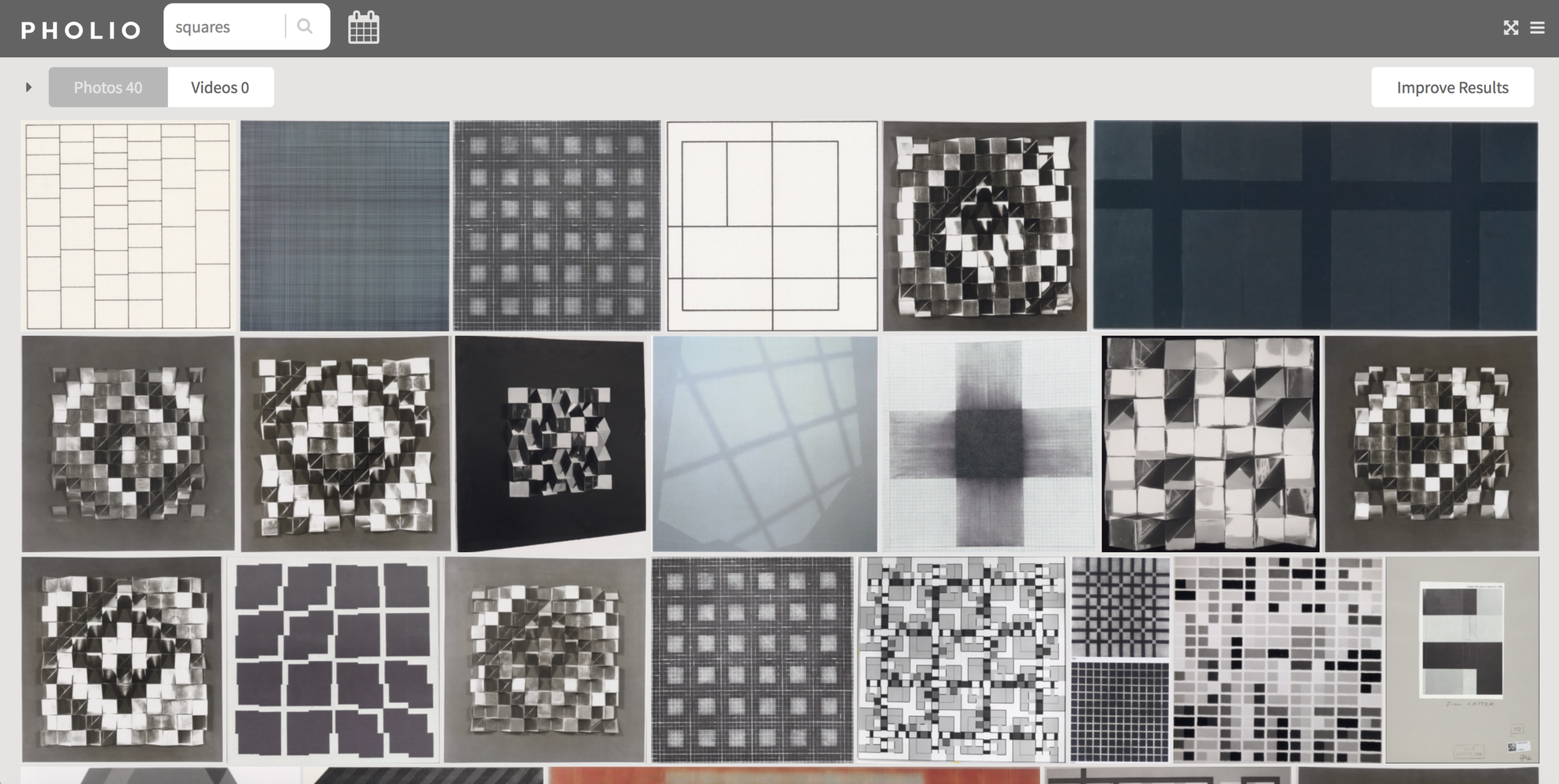
A search for <squares>

A search for <triangles>

A search for <Turner>

A search for <Constable>
N.B. These are not necessarily Turner or Constable paintings; they are paintings that ‘look like’ Turners and Constables (with Artist meta-data alongside the real paintings could be easily separated out).
“It makes tagging seem so passé”
You can still search for more well-known objects and scenes. With the full power of art history at one’s finger-tips many people’s first search is still for <cats>.

A search for <Cat>

A search for <Lion>

A search for <Windmill>
If meta-data does exist then combing that with content search can be very powerful for finding specific artworks very quickly: <Artist + Date + Subject>
Once the user finds an artwork they are interested in they can then open the full image to review it in more detail, to download, view meta-data or use it as a means to navigate to other images.
There are also some situations where text based search can be too constraining; if you are looking for something that does not translate well to a short piece of language (a type of style or brush stroke), or something that is more abstract (an emotion or feeling) or you simply have difficulty typing or thinking of what to look for, then you can use images themselves as means of navigating collections.
You can upload an image to find similar works:

The image on the left is a photograph that was captured with a Smartphone, of a print that was hanging in a Central London bar; I uploaded it into the Pimloc system to find all similar works – discovering a range of photographs of the same work that had been captured over the years by The Courtauld Institute.
I’ve searched the collection using artwork from my children (to find similar styles of work), images of famous buildings around London and also images of myself to find lost ancestors / doppelgangers.
The ability to penetrate large art collections by simply uploading a personal image creates educational opportunities for young children to start engaging in art history (ie. find someone who looks similar to me from history and then learn about them).
It allows for speedy identification of objects within images, you can directly select (tap or click) objects within images from the collection to search for similar objects in other works.

And if you’re inclined find celebrity look-a-likes from Victorian times.

The next evolution is to start making connections across art collections and to allow more graphical and quantitative querying of the worlds collection of art as a source of rich and objective historical data.
If you have an archive and are interested in finding out how Pimloc can help open your collection please get in contact: simon@pimloc.com.